

In our previous post, we discussed objectives, metrics and indicators, as powerful concepts to finely assess multiple aspects of software quality (SQ).
Using new concepts to deal with a problem is a good thing, but they add a new layer we need to understand, learn to manipulate, and integrate into our working habits.
So, let’s introduce yet another concept: the software quality rating model, and also the role-dependent rating (don’t go away just yet, I promise it will all make sense 😉)
Too much information?
As you remember, we have at our disposal metrics and indicators for everything impacting SQ.
For example we will need:
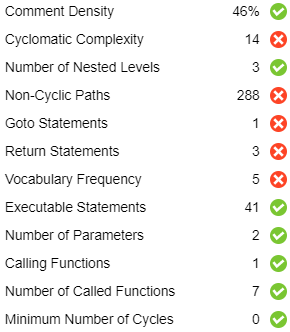
- Code coverage ratios (statement, branch, MCDC), and their expected thresholds
- Comment rates, also compared to a threshold
- Standard compliance (relatively to a set of coding rules), weighted by rules criticality
- Passed tests ratio, on a seven levels scale
Each one of these computations and indicators will have to be evaluated for each function of the project. For example, the Java code for the Jenkins project (found on GitHub) has 23k+ functions. That’s 3.4k+ classes, 1.7k+ files and 370k+ lines of code.
But we can’t parse the multitude of functions in search of the one with the bad coverage and compliance. Especially if we find out it is in a legacy class we shouldn’t touch!
That means you also need information at files and classes level. Yes, more metrics, more indicators.
At this point, we have created more data and complexity than solutions. Our work as a developer just got inundated by an ocean of interesting but frankly overwhelming data. Let’s put some order into this.
One quality rating model to understand them all
To simplify a complex problem, a common approach is to break it down into smaller manageable problems. And by doing so you can still go back to the big picture and reach a better understanding.
That is what we are doing with a software quality rating model.
A simple rating model
The big picture: What is the global quality for a whole project?
Answer: We define quality as the aggregation of code complexity, code coverage and rule compliance
The rating will be an aggregated value between complexity, coverage and rule compliance ratings.
- Sub-problem 1: How to compute complexity rating?
Answer: At project level, we compute complexity using modules complexity, which in turn are using files, and then functions complexity
The complexity rating for each level (project, module, file, function) reflects its own complexity as well as its components’
- Sub-problem 2: How to compute coverage rating?
Answer: The same principle applies, and using code coverage techniques and know-how, we’ll know how to rate a function, a file, a module and a project
- Sub-problem 3: How to compute rule compliance rating?
Answer: Again we stick to the same principle, and count the violations of a rule in the code, and compute the ratio relative to the number of rules to comply with. The rating depends on the percentage and the criticality of each rule.
Applying this simple model to all your code components produces a quality rating at project level. You can then navigate inside the project, quickly finding which components don’t comply to your quality objectives.
So in a nutshell, applying a software quality rating model to the project makes quality visible, from the project level down to the functions.
There is one thing to remember though: as powerful as it is, a model is just a simplification to make complexity easier to understand.
It might suit your needs as a developer but not your colleagues from quality or tests. Even if they are looking at the same project, they may want to assess quality differently. Fortunately, we have another concept to discover: roles.
Role-based restitution
We know that a rating model can aggregate several quality indicators into an informative rating, and help us monitor and analyze a project. But monitoring and analyzing does not necessarily mean the same thing for all stakeholders.
For example:
- A developer focuses on functions, and see where the complexity comes from
- A tester looks at test results: were all tests run, and what’s the passed ratio?
- A project manager might want to check if code coding practices are followed or not
Fortunately, it doesn’t mean we have to run as many rating models as there are people to use it.
The key to a rating model is to aggregate indicators relevant to several roles. The benefits to this approach are:
- All roles share one rating system, promoting common understanding and easier reporting
- Depending on the role, we focus on specific sub-indicators, allowing efficient analysis
In short, supporting the roles concept means designing the rating model so that it provides a generic rating, and can focus on specific views.
As a conclusion, the objective of a role-based rating model is to bring confidence:
- It crunches all the metrics and indicators data,
- so we can clearly see quality detailed on the whole project,
- and quickly find out where our attention should be directed to.
That’s a good story, but we still have to compute ratings, look for badly rated elements, check their evolution, and sort them to find the one we have to work on first.
Oh wait, and we have to do that each time the code changes!?!
No you don’t. Things are going to get so easy, stay tuned 😊
Further readings
- Software quality is not a myth: Real examples
- Software quality #5: Winning as a team
- Software quality #4: Rating model
- Software quality #3: Powers explained
- Software quality #2: To the rescue!
- Software quality #1: The origin story
- Clone spotting: Find code clones with their DNA
- Anatomy of a source code
- All code clones are not equal





