


Last week in Toulouse, France, a century-old monument weighing over 1000 tons of stone was moved to facilitate urbanization work. Disassembly was not possible without damaging the building, so it was moved instead, involving meticulous engineering.
What does this story have to do with software quality and legacy code? Well, some software projects do have large code bases, part of which can represent tens of thousands of lines, or are so old that you can’t modify them without breaking something. It is not uncommon that developers have to deal with legacy code, and develop convoluted designs to work with it.
So keeping the history part of the present is the common theme here. How can we deal with legacy code, how does it impact new development, and software quality? Let’s see how a software quality monitoring tool such as Squore answers these questions.
Dealing with legacy code
A software project is naturally constantly evolving, by adding functions, refactoring classes, and modifying algorithms. Squore’s static code analyzer keeps track of these changes, and makes sure you know what changed, and when.
The following chart helps understand the source code history visually with colored layers:
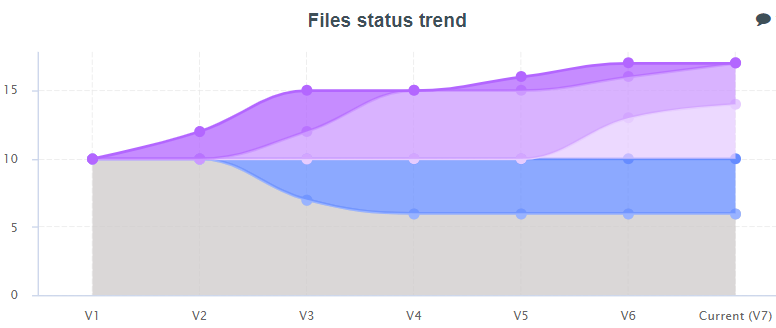

- The bottom gray layer represents the legacy code files, the ones the project started with.
- On the top layer: blue modified legacy files
- Above the “surface”, purple layers: new files. The lighter the shade, the longer these new files have remained untouched.
Keeping track of historical code, and updating history as development continues is the key to being able to efficiently focus on the code you really want to work on.
Legacy code and new development
With tagged code (Legacy or New, Stable or Active), you can easily filter it by ‘Artefact Status’. This means that you can control the scope of your analysis. For example, you can see below the same complexity heatmap chart, for all 1021 functions of a project, or just the 6 newly introduced functions.
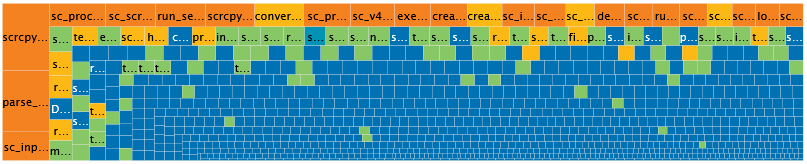

In addition to these visual and navigation aspects, Squore also integrates history into the technical debt computation.
Typically, the technical debt is going to evaluate how costly it would be to fix all issues for all code (legacy and new).
But we can also learn how much it would cost to fix yesterday’s commit, if we only consider the modified code. This is valuable information, because it is much easier and more efficient to fix recent code that is fresh in our memory than old code potentially more difficult to maintain.
It doesn’t mean we ignore old code, of course, but that we can choose to focus on code depending on its tags.
Software quality on legacy code
What can we do to integrate sometimes bulky legacy code in software quality monitoring and not drown under millions of rule violations when we run code checkers on the whole code?
Using Squore’s ‘Legacy Components’ flag when creating a project is useful when you don’t want the legacy code to interfere:
- All rule violations (aka ‘findings’) found on the code are considered as ‘legacy’, and will be automatically ‘relaxed’ as such.
These relaxed finding are still there, but won’t participate to standard compliance metrics and indicators - The side effect being that as the project evolves, new findings will be easy to track and review, whatever their origin (from new code or modified legacy code)
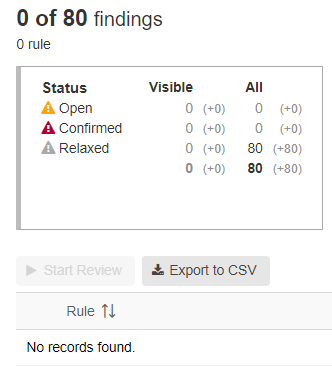
In the example below, we created a simple project with the ‘Legacy Components’ flag, resulting in 80 relaxed findings. With the next development iteration, 3 new findings appeared and can be reviewed.
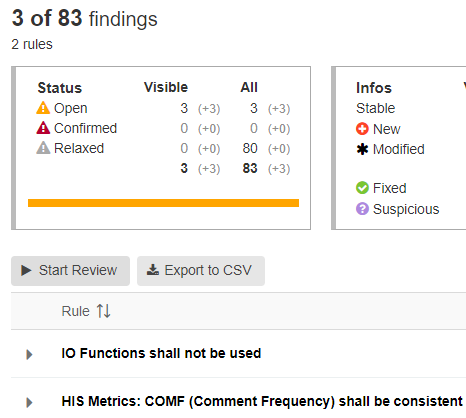
Of course, you can also integrate legacy code in the project’s software quality monitoring. Then use features such as criticality filtering or test analysis to pinpoint parts of the code needing attention.
Conclusion: How to deal with legacy code
History is important, and legacy code needs to be part of the software quality monitoring process. By combining the code evolution analysis with quality indicators computations, tools like Squore can help identify where to act, and why.
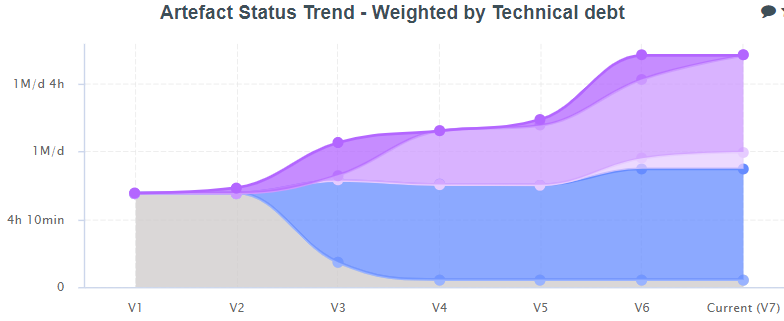
As a final example, this chart shows the technical debt, or cost to fix issues, depending on the code’s historical tagging
- The gray unchanged legacy code technical debt gradually decreases to almost zero.
This means that the remaining untouched legacy code has very few critical issues - However, there’s something wrong.
The blue area represents the technical debt for the changed legacy code.
Instead of staying horizontal, this level increases, which means we have modified our legacy code, and introduced additional technical debt into it - As for the purple areas, they tell the technical debt story of our new code.
It is not uncommon to see this level rise, but we should address it anyway.
Further readings
- Measuring and monitoring technical debt
- Software quality temporal monitoring: Back in time
- Squore Showcase – Find out more about Squore in a practical example
- Squore product information: Analytics for project monitoring





